Using Deep Learning to Power Multilingual Text Embeddings for Global Analysis, Part I
A crash course in basic text embeddings
A chronic problem with using machines to analyze human language is that the same meaning can be expressed using many different words. Take for example the sentence “Joe Smith was educated at Harvard.” There are many ways to express this relationship: Joe Smith studied at Harvard, Joe Smith took classes at Harvard, etc., and teaching a machine all the different variations is costly and time consuming. However, what if you could train an algorithm to assign similar numerical values to similar phrases of text? When given a new phrase, the machine would be able to accurately estimate its meaning based solely on its numerical representation.
That’s where text embeddings come in. Text embeddings ease the challenges of programmatic language analysis by transforming text into numbers, or more accurately, vectors. Remember vectors from high school algebra and physics? That’s what’s in play here. These numerical word representations make it possible to mathematically represent words, phrases, and entire documents. With text embeddings, a machine can determine that document A bears more similarity to document B than document C the same way we know that 1 is closer to 2 than it is to 55.
Babel Street Text Analytics supports text embeddings in five languages: English, simplified Chinese, German, Japanese, and Spanish. Additionally, since Text Analytics maps all five sets of text embeddings in the same vector space, you can compare or find words with similar meanings, whether it’s “university,” (English) “大学,” (Chinese) or “universidad” (Spanish) and other related words without any actual translation.
How do text embeddings work?
Text embeddings are the cutting edge of today’s natural language processing and deep learning technology. To create them, we take a big pile of text and represent each word, phrase, or entire document with a vector in a high dimensional space (similar to a multi-dimensional graph). You may have heard of “word embeddings,” and they work the same way, but only represent individual words. Once text has been mapped as vectors, it can be added, subtracted, multiplied, or otherwise transformed to mathematically express or compare the relationships between different words, phrases, and documents.
The case of the pencil and the wombat
Let’s take a very simple example. Say we’ve represented a collection of individual words with vectors, including “pen” and “pencil.” When we look at our vector space, we’d expect those vectors to be close to each other, given their similarity, as shown in the example below (a highly simplified visualization of word embeddings in a vector space).
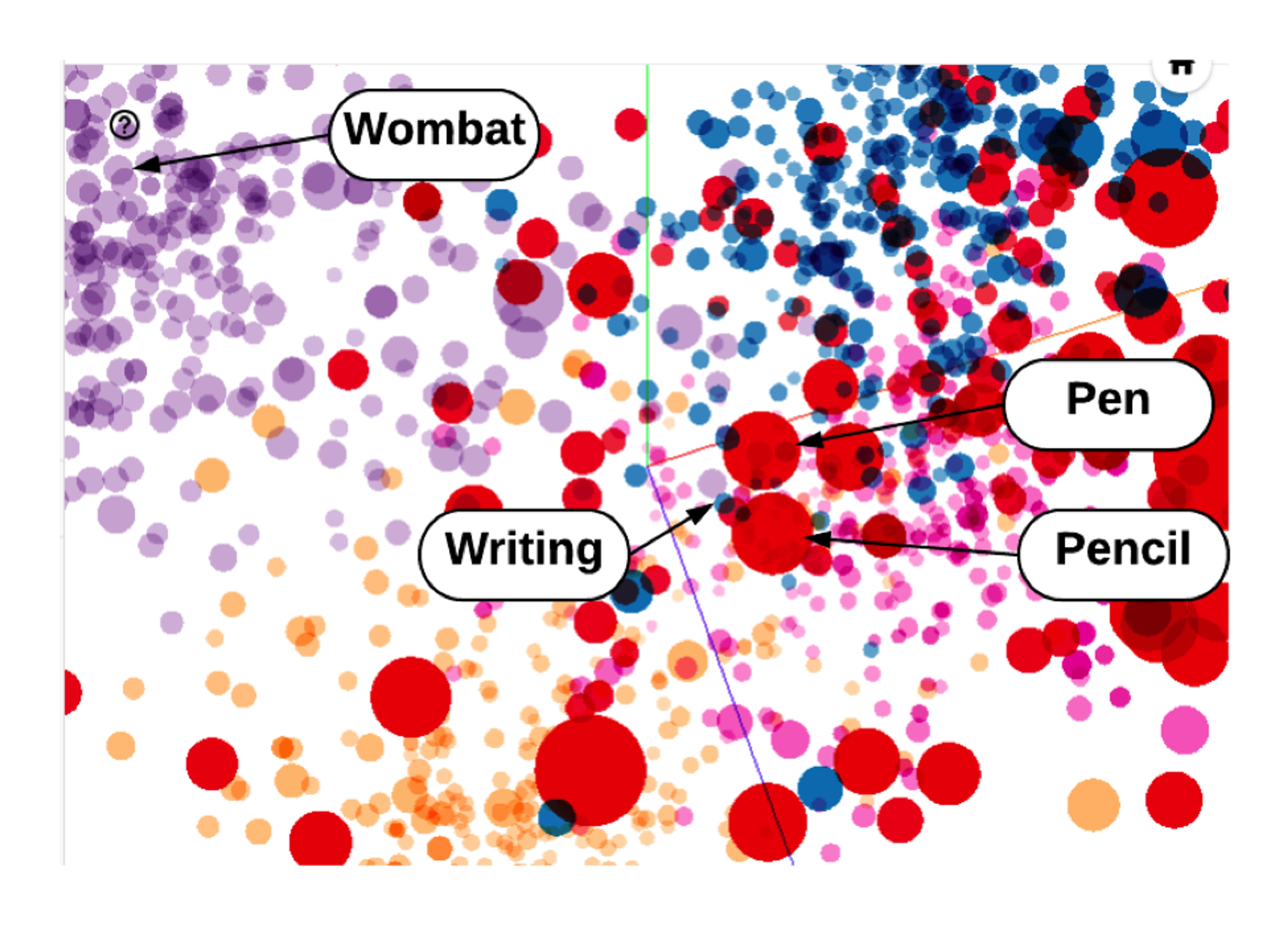
“Pencil” and “wombat” on the other hand, we’d expect to be much further apart. “Writing” and “pencil” we’d also expect to be close together, but perhaps in a different way than “pen” and “pencil.” Not so complicated, but when you add millions of words and multiple languages to the mix, things can get thorny. To account for this, the vector spaces housing word embeddings often contain hundreds of dimensions.
Learn More
Intrigued? Part II of this blog expands on ways you can use the power of text embeddings.
Or, download a technical brief that explains how Babel Street Text Analytics (formerly Rosette) calculates semantic similarity.