Entity Extraction, Entity Resolution, and Why They Matter

Modern investigations undertaken by government and military agencies, the broader intelligence community, and large enterprises all depend on understanding who’s who, and what’s what across vast volumes of unstructured data. Entity extraction (also called “named entity recognition”) is a natural language processing technique that culls entities — people, organizations, dates, locations, and more — from unstructured data sources. Along with an intertwined process called “entity resolution,” entity extraction is a key step in transforming raw data into actionable intelligence.
How entity extraction works
Imagine that an entity extraction system is reading billions of pieces of unstructured data — social media posts, news articles, message board communications, government records, corporate reports, blogs, personal web sites, audio transcripts and more. Much of it yields minimal entity information. The system scans poems about cats. Movie reviews. AI-generated recipes. Suddenly, it encounters this line of text in an article from a local newspaper:
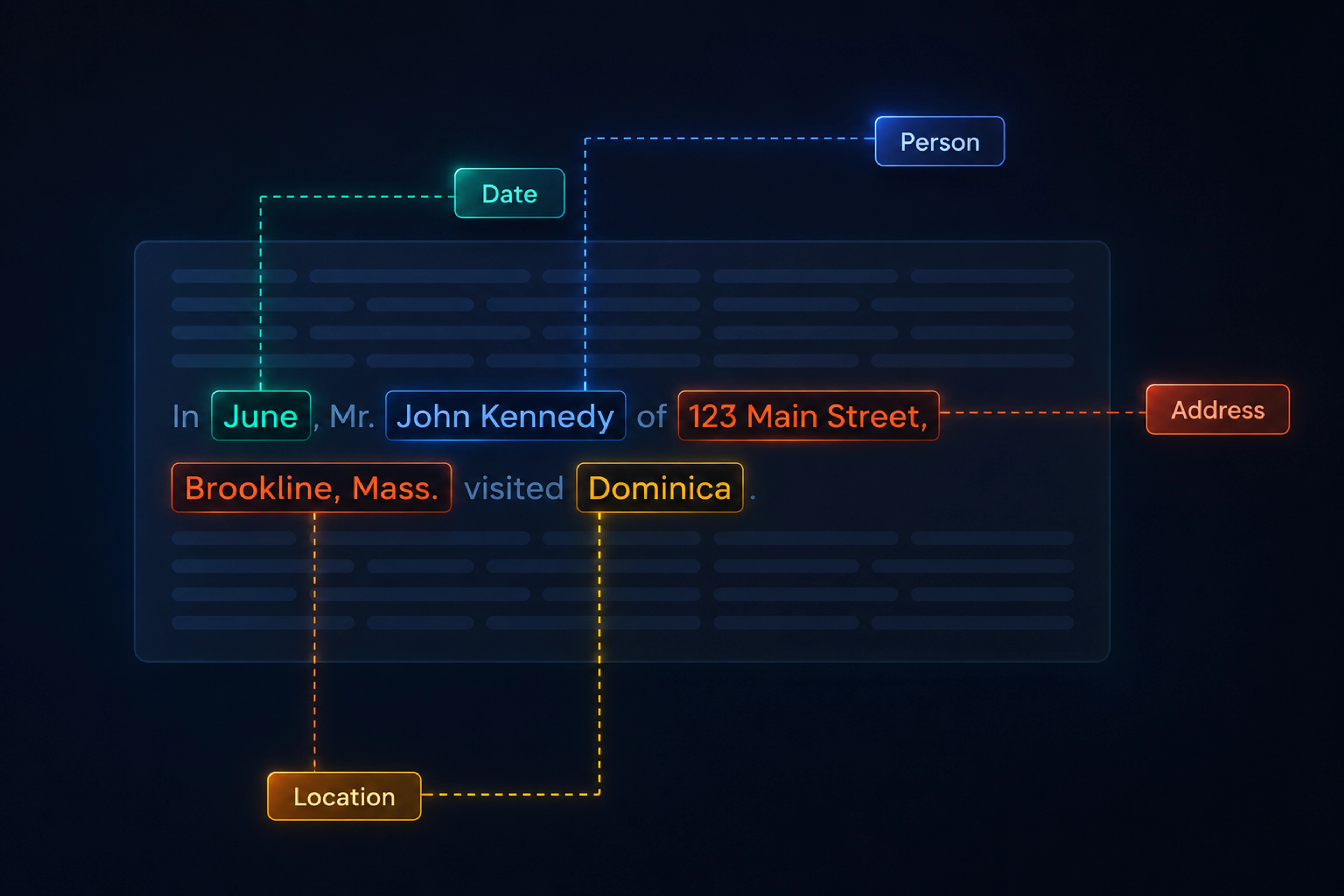
In June, Mr. Kennedy visited Dominica.
Specific words and word patterns in this sentence alert the system to the presence of three entities: June, Kennedy, and Dominica. The system then works to classify each of these entities into a predefined category (a person, an organization, a location, a date/time, or other category) and create a structured record for each entity.
AI-powered classification algorithms use context clues and other insights to determine that, in this sentence:
- June is a month — part of a date — not a woman’s name. (As indicated by use of the word “in.”)
- Kennedy is a person, not the township in Allegheny County, PA. (As indicated in part by use of the title “Mr.”)
- Dominica is a location/nation, not a person. (Implied by the lack of a last name.)
This may be all the entity information the system can extract from this simple sentence. But suppose the newspaper reporting on the Kennedy trip went into a little more detail. It published a sentence that read:
In June, Mr. John Kennedy of 123 Main Street, Brookline, Mass., visited Dominica.
The entity extraction system detects this additional information. It both standardizes it and appends it to the Kennedy record. As a result, “Mr. John Kennedy of 123 Main Street, Brookline, Mass.” becomes a record reading:
First Name: John
Last Name: Kennedy
Street Number: 123
Street Name: Main
City: Brookline
State: MA
During this process, entity extraction systems may also enrich records. For example, ZIP+4 codes and geolocation coordinates may be added to addresses. Likely gender may be appended to names.
Next steps: entity resolution
Once entities have been extracted, entity resolution can occur. Entity resolution is the process of finding and linking records referring to the same entity in and across massive, evolving data sets.
How does this differ from entity extraction?
Entity extraction has already found mention of a person named “John Kennedy.” But which John Kennedy is he? The president? The president’s son? Or any of the other thousands of people worldwide named John Kennedy?
Organizations need entity resolution to make these types of determinations. Without it, the U.S. Department of State doesn’t know if the Kareem Al-Hassan, London teacher seeking a visa to visit New York City with his family, is the same person as Kareem Al-Hassan, Captagon trafficker. Or كريم حسن, a known plunderer of architectural sites who smuggles antiquities into the United States. Law enforcement agencies cannot connect aliases used by the same offender in different investigative jurisdictions. In the private sector, financial institutions cannot adequately compare names against sanctions lists.
How does entity resolution help government, military, intelligence, and private organizations make these connections? Entity resolution tools scour massive amounts of PAI to find identifying information and append it to each named entity. These identifiers can include age, gender, street addresses, email addresses, telephone numbers, family connections, employment, education, and more. Use of identifiers helps analysts and investigators link or distinguish between one John Kennedy and another, one Kareem Al-Hassan and another. Similar identifiers can be applied to corporate entities.
How Babel Street can help
Entity extraction is a key component of the Babel Street Agentic Risk Intelligence Platform. This is an AI-native operational framework in which governed AI agents execute, synthesize, and deliver structured, decision-ready intelligence. Setting a new standard for identity risk intelligence, strategic threat intelligence, and vendor risk intelligence, this platform helps organizations outpace dynamic threats by searching vast amounts of PAI to provide panoramic, up-to-the-second insights. These insights are based on AI-powered analyses of our vast pipeline of rights-cleared, mission-curated, multilingual data — data that other providers can’t access or replicate.
By automatically extracting people, organizations, locations, and more — regardless of different languages, naming conventions, formatting, alphabet types, grammar structures, and other data components — Babel Street provides rapid, trustworthy insight.
Our AI-based entity extraction uses machine learning models to analyze text and automatically extract and enrich entities as data enters our system. This capability treats entities as first-class analytic objects rather than raw text strings — improving discoverability and empowering scalable analyses. In addition, Babel Street identifies and indexes key entities as metadata. This metadata persists across workflows.
Additional entity extraction capabilities include:
- Native-language processing — Many platforms translate data to English before extracting entities. This process can lead to compounding errors, particularly when extracting entities from documents written in complex languages such as Arabic, Chinese, Japanese, Korean, Persian, and Russian. Babel Street minimizes the chance of error by extracting entities directly from native-language text.
- Entity-based refinement — This capability empowers users to build searches using entity filters combined with keywords; see extracted entities surfaced directly in document results; and use these entity refinements to reduce noise and improve search precision.
Working with Babel Street, government, military, intelligence, and enterprise organizations can expect to obtain:
- Consistent intelligence at scale
- Faster entity discovery in large, complex datasets
- Better understanding of unfamiliar investigative landscapes
- Improved investigative workflows
Babel Street has spent more than a decade serving the military, defense, intelligence, and enterprise communities with mission-grade risk intelligence. The entity extraction capabilities of the Babel Street Agentic Risk Intelligence Platform act as the foundation for the type of intelligence that protects nations, empowers organizations, and creates a safer world.
Learn the basics of entity extraction

Babel Street Insights Entity Extraction
What is Entity Extraction?
What’s the Difference Between Entity Extraction (NER) and Entity Resolution?
Entity extraction, or named entity recognition (NER), is finding mentions of key “things” (aka “entities”) such as people, places, organizations, dates, and tim...
Feature Spotlight: Enhanced Entity Extraction in Babel Street Insights
How entity extraction transforms unstructured data into actionable intelligence for OSINT teams
Disclaimer
All names, companies, and incidents portrayed in this document are fictitious. No identification with actual persons (living or deceased), places, companies, and products are intended or should be inferred.