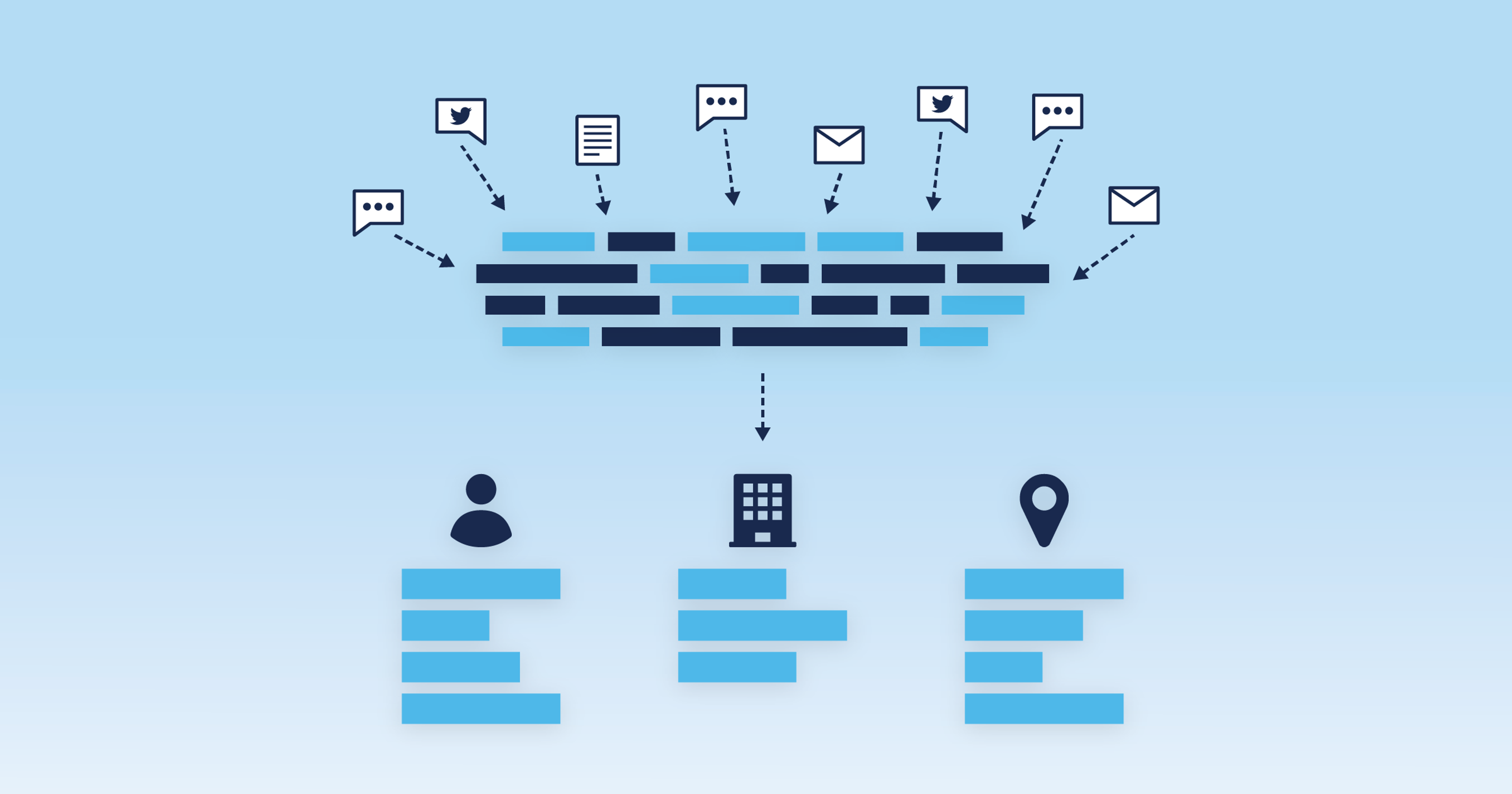
How it’s used and how it works
Entity extraction (aka, named entity recognition or NER) is a type of natural language processing technology that enables computers to analyze text as it is naturally written. Specifically, it pulls out the most important data points (entities) in unstructured text (think news, webpages, text fields). Entities include names of people, places, organizations, and products, as well as dates, email addresses, and phone numbers. Extracted entities can populate a database record about the text. This structure enables higher-level analyses, such as relationships between entities, detecting events, and sentiment analysis around entities.
What is named entity recognition used for?
Better search for e-commerce, business research
Extracted entities make keyword search more accurate. Keywords only match words, whereas entity extraction uses context to know when, for example, “Paris” refers to a city, the name of a person ("Paris Jones"), or a nonentity (plaster of Paris). In e-commerce, extracting price, clothing features, size, and other product attributes from descriptions lets shoppers filter searches to refine 200 results to a browsable 20.
Brand monitoring and intelligence gathering
Want to know “what are people saying” about a new product launch or their experience at your hotel? NER is an enabling technology for sentiment analysis to track social media buzz or uncover new rivals. Intelligence agencies that track specific people and organizations of interest in message streams can distinguish between similarly named entities (e.g., Richie Fox the astronaut or hockey referee) by linking to an entity knowledge base using the context surrounding the entity. (Does the text refer to space or hockey?)
Knowledge graphs, event extraction, fact extraction
Pushing the possible are technologies built on NER:
- Knowledge graphs visualize the relationship between entities (who is affiliated with what organizations and locations)
- Fact extraction answers factual questions (What kills bacteria?)
- Event extraction finds who did what to whom, when, and where.
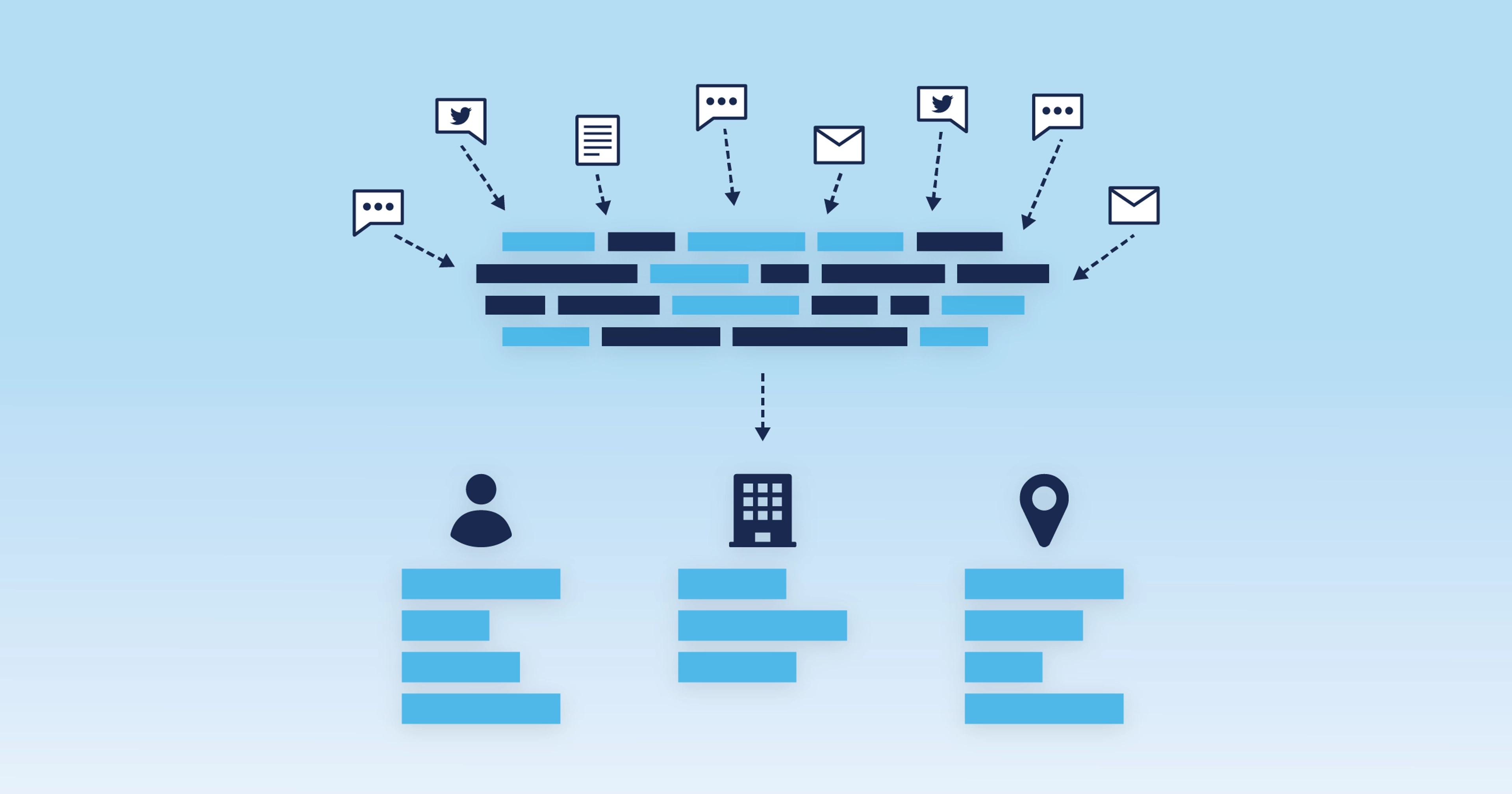
Especially for these advanced technologies, entity extraction must be highly accurate and chain together different mentions of the same entity. This is also known as coreference resolution.
How entity extraction works
Different techniques are used to extract different types of entities.
Machine learning trains models to extract entities such as person, location, and organization where word meaning varies depending on context (e.g., Paris). A corpus of text containing thousands of examples of each entity type is annotated by humans. Then an algorithm trains a statistical model on that data to “learn rules” for predicting which words represent which entity type.
The accuracy from machine learning models depends on the algorithm used and, even more so, creating high-quality training and test data. Deep learning models can be more accurate than traditional machine learning models, but are currently much slower. Optimizing the accuracy of a model means adapting the statistical model to that set of data.
The exact match method matches words against a list of entities for each entity type. This method is appropriate for entity types that are finite and unambiguous, such as nationalities. However, since exact match doesn’t consider context, it cannot distinguish between the nationality “Polish,” and the common word “polish.”
Pattern matching is effective for finding entities that follow a particular pattern, such as email addresses, URLs, and phone numbers.
Applications that analyze big data to find insight from patterns and themes in unstructured text depend on entity extraction, and will only continue to grow.
Disclaimer: All names, companies, and incidents portrayed in this document are fictitious. No identification with actual persons (living or deceased), places, companies, and products are intended or should be inferred.
Frequently Asked Questions
What is entity extraction in natural language processing?
Entity extraction is an NLP technique that identifies and labels key information — such as people, places, organizations, and dates — within unstructured text. It helps transform raw language into structured data that machines can analyze. Modern entity extraction solutions rely on machine learning to improve accuracy over time. This process is foundational for many AI-driven text analysis applications.
Why is entity extraction important for data analysis?
Entity extraction surfaces meaningful details from large volumes of text, making it easier to analyze patterns and relationships. It turns unstructured data into searchable, structured insights that support faster decision-making. This accelerates workflows like risk analysis, content classification, and trend detection. As datasets grow, strong entity extraction becomes critical for scaling data intelligence.
What types of entities can be extracted from text?
Common entity types include people, organizations, locations, dates, and numerical values. More advanced models can extract domain-specific entities such as medical terms, financial indicators, or product names. Some systems also detect relationships between entities. The variety of supported entity types depends on the sophistication of the extraction solution.
How does entity extraction differ from keyword extraction?
Keyword extraction identifies the most relevant words or phrases within text based on frequency or importance. Entity extraction goes further by classifying those terms into specific categories like names, places, or events. Keywords help summarize topics, while entities help structure precise information. Together, they provide complementary views of unstructured data.
What industries benefit most from entity extraction?
Industries with large volumes of unstructured text — such as finance, government, security, legal, and healthcare — benefit greatly from entity extraction. It helps analysts quickly surface relevant information from documents, reports, and online content. Businesses also use it for customer insights, fraud detection, and compliance. Any organization that depends on text-driven intelligence can gain value from strong entity extraction capabilities.
How does AI-based entity extraction work?
AI-based entity extraction uses machine learning models to analyze text and automatically identify people, places, organizations, and other defined categories. These models are trained on large datasets to recognize patterns in language and context. Advanced systems also use deep learning to detect relationships between entities. This enables more accurate and scalable text analysis than rule-based methods alone.
What challenges exist in multilingual entity extraction?
Multilingual entity extraction must handle different alphabets, grammar structures, cultural naming conventions, and ambiguous terms across languages. Low-resource languages often have limited training data, which reduces model accuracy. Idioms, slang, and transliteration add complexity to cross-language interpretation. Effective multilingual solutions require broad language coverage and domain-specific tuning.
How accurate is automated entity extraction?
Automated entity extraction can achieve high accuracy when supported by modern AI models and well-trained datasets. Performance varies based on text quality, domain specificity, and language complexity. Accuracy improves significantly with continuous model training and human-in-the-loop review. Many organizations use hybrid approaches to achieve near-enterprise grade precision.
How is entity extraction used in intelligence analysis?
Entity extraction helps intelligence teams quickly identify key individuals, locations, and organizations across large volumes of data. It surfaces connections between entities to reveal patterns, networks, or potential threats. Analysts use these insights to accelerate investigations and improve situational awareness. This makes entity extraction a core capability in modern intelligence workflows.
What data sources can entity extraction be applied to?
Entity extraction can be applied to documents, reports, emails, social media posts, news articles, chat logs, and other unstructured text sources. It also works with multilingual and noisy data from online platforms. Organizations use it to process both internal records and publicly available information. This flexibility makes entity extraction valuable across many analytic environments.
What entity extraction tools are best for intelligence teams?
The best tools combine multilingual data access, AI-powered extraction, and workflows built for investigations. Babel Street enriches large volumes of publicly available information with entity extraction, sentiment, event, and relationship detection — purpose-built for intelligence use. Its APIs also expose advanced extractors and linkers so teams can operationalize results at scale.
How does Babel Street handle complex entity relationships?
Babel Street performs entity extraction, linking, and co-reference resolution to connect people, places, organizations, and events, then surfaces relationships for analysis. These capabilities underpin entity-centric sentiment, event, and relationship extraction workflows used by intelligence and law enforcement teams.
Can entity extraction be customized for law enforcement use cases?
Yes — Babel Street provides configurable extraction, cross-lingual name matching, and investigation-ready workflows tailored to law enforcement requirements. Solution bundles integrate secure, anonymous web research with multilingual analytics so agencies can adapt entity extraction to specific missions.
How does Babel Street improve entity resolution accuracy?
Babel Street improves entity resolution accuracy by combining advanced AI models with multilingual data enrichment to correctly link people, organizations, and locations across complex datasets. Its extraction and linking engines reduce false positives by understanding context, relationships, and linguistic variations. The platform also applies entity co-reference resolution — such as connecting pronouns or alternate spellings — to avoid missed matches. This results in clearer, more reliable identity matching for high-stakes intelligence and investigation workflows.
How does entity extraction integrate with OSINT platforms?
Babel Street exposes APIs that deliver enriched, structured outputs — entities, links, and salience scores — that plug into existing OSINT and case management systems. Its managed attribution capabilities ensure analysts can safely collect, enrich, and feed open-source data into downstream workflows without operational risk. management systems.