What Does It Mean to Support Persian Text Analytics
A language with many names
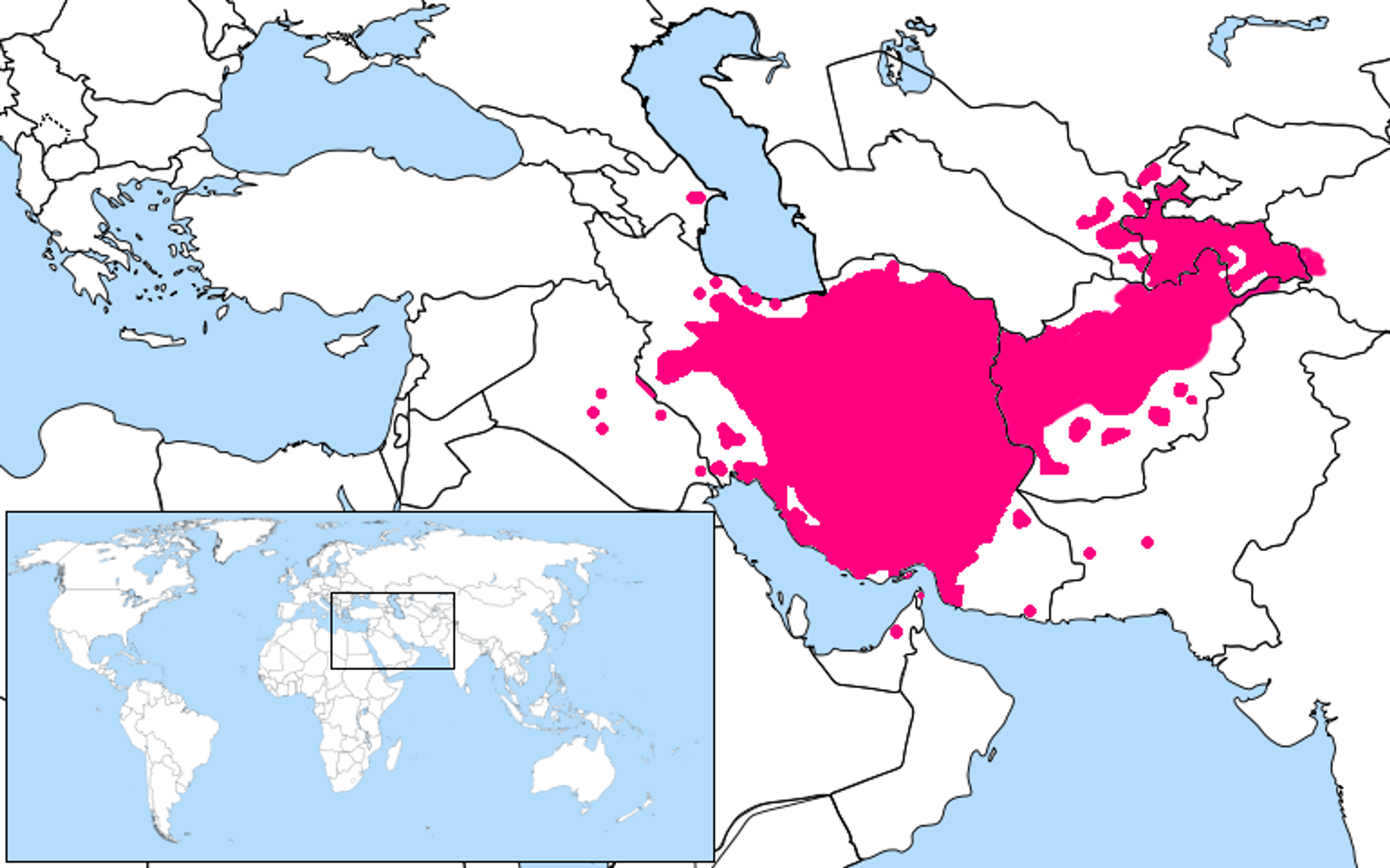
The modern Persian language has a lengthy history, with spoken roots going back 4,000-5,000 years. Since then, the language has evolved enormously in response to geopolitical events, technological advancements, and cultural blending to create the language spoken by 110 million people today.
Persian has many alternative names, including Parsi, Farsi, Dari, and Tajik, leading to significant confusion when attempting to find text analytics solutions to handle Persian text.
The Persian language as we know it is actually called “Parsi” among its speakers. The word “Persian” is the Greek translation of the word “Parsi.” Despite this, Persian has been adopted for wider use by the Western world, although some parts of the world continue to refer to the language as “Parsi” and its speakers as “Parsis.”
When Parsi began to be written in Arabic script instead of its original cuneiform some three thousand years ago, a direct translation was not possible. The Arabic alphabet does not have the letter “P,” thus the term “Farsi” was born. “Parsi” and “Farsi” are interchangeable from the perspective of evaluating software. Sometimes Farsi is also called “Western Persian,” “Iranian Persian,” or “Western Farsi,” especially to specify Farsi spoken in an Iranian — or Tehranian — accent and dialect.
The birth of Dari
Dari became the official language of Afghanistan in 1964. In practice however, “Dari” is another name for the same language. Distinguishing Dari as the national language was less about linguistics and more a political decision to distance Afghanistan from its cultural and historical ties to the Persian-speaking world, namely Iran.
While there are some vocabulary and phonology differences between Farsi and Dari, they are no more remarkable than those between American and British English. The Brits say “lorry” where the Americans use “truck,” but from the perspective of an algorithm, the languages are the same. Similarly, the word for “kite” is badbadak (بادبادک) in Western Farsi, but kaghazparan (کاغذ پران ) in Dari.
Tajik: A new script
In addition to overlapping phonology, Farsi and Dari also share the Persian alphabet: a variation of Arabic script that includes a few additional letters not found in Arabic. This is not true for Tajik, the name of the Persian spoken in Tajikistan. Because Tajikistan was formerly part of the Soviet Union, Tajik uses the Cyrillic alphabet.
How can two languages with a different alphabet be the same? At its root, language is oral first, then written. A Dari speaker and a Tajik speaker would be able to understand one another, but they would not be able to read each other’s writing.
From a text analytics perspective, the same model can usually be used to analyze Dari and Farsi text, but not Tajik. That said, Tajik is still very closely aligned with its Arabic-scripted cousins. Transliterating — a far less error-prone process than machine translation — Tajik text from Cyrillic to Arabic allows it to be processed by the same algorithms used to analyze Dari and Farsi.
Processing Persian names
One notable exception to the universal application of Persian text processors is handling name-centric data. Phonetic variations are much more significant between names. Furthermore, accurate name matching is vital for several high-risk use cases like border security and financial compliance.
Take the Persian name وليد. In Dari (Afghani Persian) it’s pronounced Waleed, but in Western Farsi (Iranian Persian) it’s pronounced Valeed:
“Valeed Ahmadi” and “Waleed Ahmadi” are likely to be alternate transliterations referring to the same person. Knowing this means fewer missed matches and better name search and discovery.
The name transliteration and matching capabilities of Babel Street Match were trained on distinct Farsi and Dari data to be able to understand this differentiation. You will see support for both “languages” in the documentation instead of just “Persian.”
Find the right model for your data
Even within a single country, regional variations and accents exist. Individuals in different parts of the United States use the words “pop,” “soda,” or “coke” to refer to a sweet carbonated beverage. Similarly, a Minnesotan has a distinct accent from a person in Alabama.
The same is true for speakers of Farsi, Dari, and Tajik. Each “language” has its distinctions from the others, but for the purpose of text analysis, one engine is often sufficient for all three.