Accurate Language Identifier for Queries & Tweets

The language identification function in Babel Street Text Analytics has been improved to solve the problem of language detection for short texts. Existing language detectors require many words to confidently identify the language of a string of text, and are therefore unreliable when trying to detect the language of queries, tweets, photo captions, etc. Text Analytics can reliably detect the language of text as short as one to four words, or as little at 20 bytes.
Why identify language in short text?
Short text can be a rich source of information and comes in many forms. From microblogging sites such as X (formerly Twitter) and Sina Weibo, to queries, chat, text messages, image captions, metadata and article titles. Many organizations, both commercial and government, recognize that properly identifying the language of these short strings is the key to the next stage in any analysis pipeline. Whether it is presenting a web user with search results that match the language of their query, or applying the appropriate machine translation engine to article titles and image captions to make content accessible to a wider audience.
Tested and proven - language identification software
The short texts feature was tested against two common open-source language detectors, using a never-seen-before test set of tens of thousands of real-world social network search strings. Text Analytics more than doubled the accuracy of the open-source language_detection library, achieving 83% accuracy. Text Analytics was also about 66% better than the ldig open-source language detector, specifically designed for tweets.
Comparison of language detectors against a short string text
(1.0=perfect accuracy)
When focusing on the average accuracy per language, Babel Street is 75% accurate, as compared to the other three detectors which all hover around 41-44%.
*Overall Accuracy measured accuracy of the entire test set, which was 77% English. (This language imbalance, in fact, reflects reality in which English makes up about 70% of all search queries).
How short string language identification tool works
Text Analytics achieved short-string language detection by adding language-aware methods to the language-agnostic, character-level n-gram approach almost universally used by language detectors. Most language identifiers create statistical profiles for each language, by taking a whole lot of text in each language, chunking it into overlapping sequences of 3-4 bytes, and keeping a count of the unique sequences.
Example of n-gramming "weather radar”
The frequency of these n-grams differs based on language. The language of an unknown text (which is also chunked into n-grams) can be guessed by finding the language whose statistical profile it most closely resembles. However, when the “unknown text” is short, accuracy based on a handful of n-grams is dubious at best.
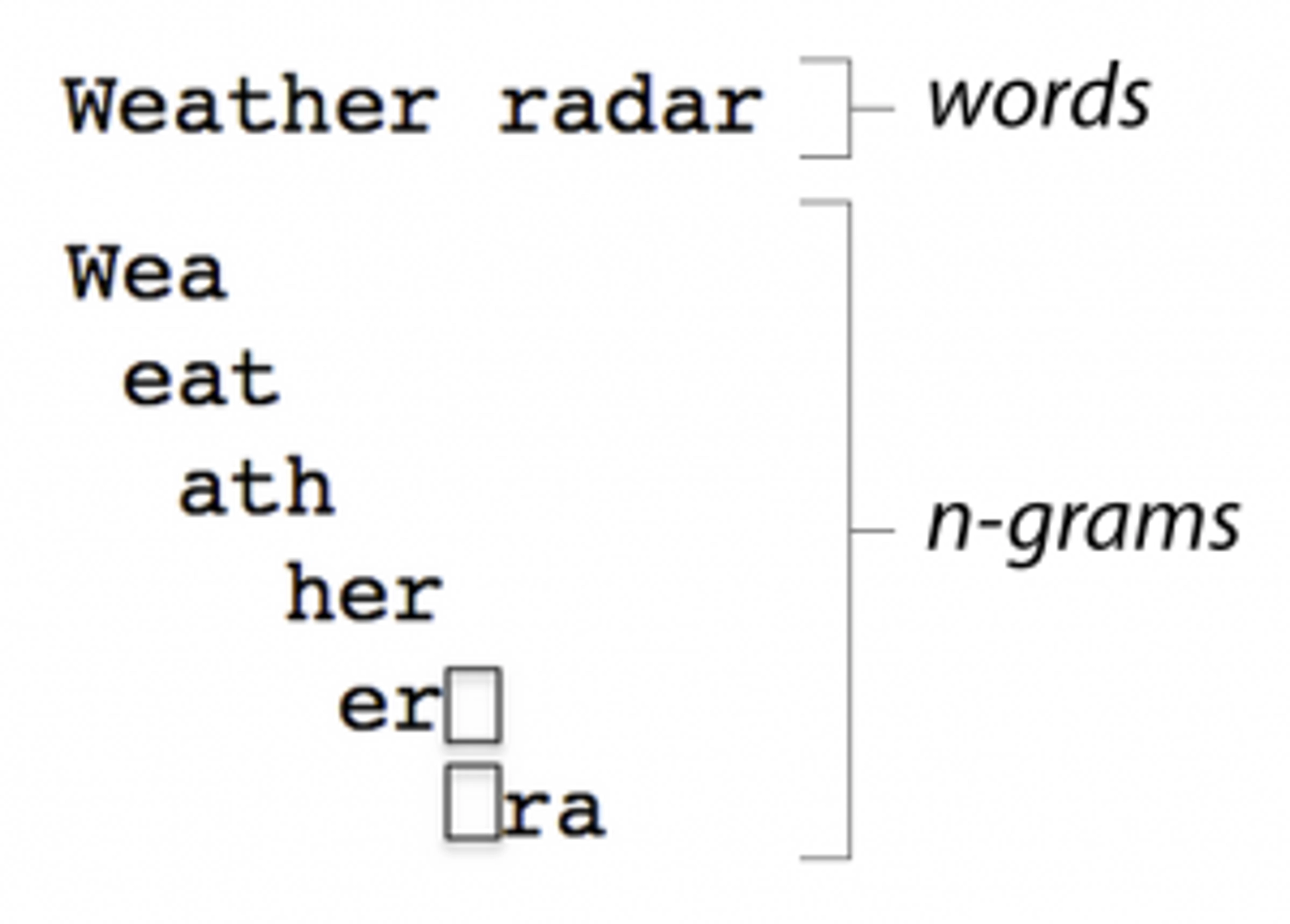
Text Analytics added more language-specific information, including word- and script-level awareness. Think about how easy it is to recognize “weather radar” as English. Those two words are very discriminative, whereas it’s much harder to say if “wea, eat, ath, …” are more prevalent in English than another language.
Word-level (or token-level) awareness exploits the fact that words are also unique to, or much more likely in one language than another. A word like “knight” indicates English at least as well as the “ight” combination.
Script awareness exploits the fact that certain languages have their own alphabet. If the text is in a language like Greek, then we can confidently say “It’s Greek” based on the script.
Text analytics availability
Within Text Analytics, users simply set a character threshold, and the short string models will be applied to the identification of strings below that threshold.