
Methods of name matching and their strengths and weaknesses
In a structured database, names are often treated the same as metadata for some other field like an email, phone number, or an ID number. But what happens if you only have a name to lookup a record? This happens quite frequently since humans tend to prefer names to numbers and laws may prevent ID numbers from being created or shared.
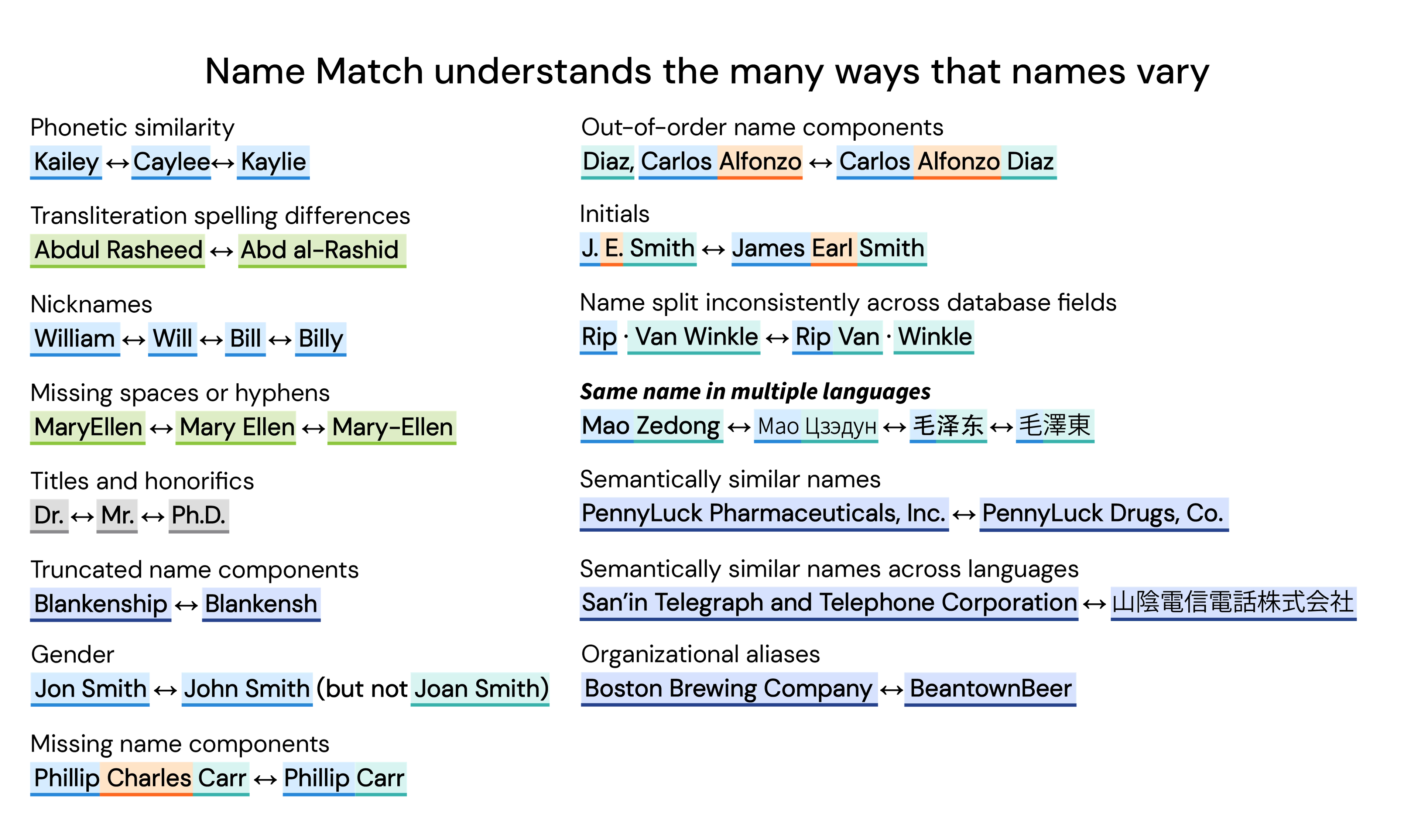
When names are your only unifying data point, correctly matching similar names takes on a greater importance, however their variability and complexity make name matching a uniquely challenging task. Nicknames, translation errors, multiple spellings of the same name, and more all can result in missed matches. While there is an abundance of search tools on the market, name search is a different animal than document search, and requires a fundamentally different approach.
Different name matching methods are best suited to solve different name matching challenges. There are many ways to match names, but no one universal solution. The best name matching software uses a hybrid of multiple methods to address the maximum number of name variations:
- Common key method
- List method
- Edit distance method
- Statistical similarity method
- Word embedding method
Each of these methods excels at solving one or several of the many challenges to accurate and consistent matching:
Common key method
Pros: Fast execution, high recall
Cons: Mostly limited to Latin-based languages; transliterating non-Latin names reduces precision
These methods reduce names to a key or code based on their English pronunciation, such that similar sounding names share the same key. A well-known common key method is Soundex, patented in 1918. For example, Cyndi, Canada, Candy, Canty, Chant, Condie share the code C530.
Many methods take a similar approach to Soundex, including Metaphone and Double Metaphone. These methods use phonetic algorithms which turn similar sounding names into the same key, thus identifying similar names. Metaphone expands on Soundex with a wider set of English pronunciation rules and allowing for varying lengths of keys, whereas Soundex uses a fixed-length key.
Double Metaphone further refines the matching by returning both a primary and secondary code for each name, allowing for greater ambiguity. In addition, instead of being tied to English pronunciation of characters, it attempts to encompass pronunciations of other origins such as Slavic, Germanic, Celtic, Greek, French, Italian, Spanish, and Chinese.
For example, Double Metaphone encodes “Smith” with a primary code of SM0 and a secondary code of XMT, while it tags “Schmidt” with a primary code of XMT and a secondary code of SMT. That the names share a primary and secondary code of XMT indicates a degree of similarity between the names which Soundex perhaps overstates and which Metaphone misses.
While the common key method is fast to execute and has good recall, the precision suffers. Manual inspection of a few names reveals the precision issues. These names share the Soundex key H245: Haugland, Hagelin, Haslam, Heislen, Heslin, Hicklin, Highland, Hoagland.
Metaphone does a better job than Soundex, encoding the above names with different codes except for the very similar pairs Haugland/Hoagland and Heislen/Heslin.
For cases where name similarity is being scored against pairs of names in different scripts — for example Korean Hangul vs. English — the name must first be converted to Latin characters, which potentially introduces more errors to the comparison.
Particularly in languages such as Japanese where one character can have more than one correct pronunciations, converting first to the Latin script can introduce fatal mistakes. The common Japanese female name 洋子 can be correctly pronounced Yoko or Hiroko.
Transliteration of names (a mapping of characters or sounds in one script to another) produces many possible variations since sounds in one language have to be approximated. Variations introduced by transliteration increases the complexity of the already difficult task of matching names.
If الرشید عبد is being evaluated against Abdal-Rachid, but the transliteration of الرشید عبد produces Ar-Rashid, will the names come back as a match — as they should?
One common key method, the Beider-Morse Phonetic Matching algorithm, does accept Russian in Cyrillic script and Hebrew in Hebrew script, but is otherwise Latin-bound.
List method
Pros: Easy to maintain
Cons: Computationally intensive (read: expensive hardware needed to run against long lists of names quickly); Cannot handle names the system doesn’t know about; Cannot handle names with missing/added spaces between components; Cannot handle names split between different fields; May require unacceptably long processing time for long, multi-component names (5+ components).
This method attempts to list all possible spelling variations of each name component and then looks for matching names from these lists of name variations. For example, one system produced 3,024 possible transliterations of this Arabic name “الرشید عبد“ since each separate name component alone has several variations. Here are the first five and last five variations.
1. Abdal-rashid
2. Abdal-rashide
3. Abdal-rasheed
4. Abdal-rashiyd
5. Abdal-rachid
…
3020. ‘Abd-errshiyd
3021. ‘Abd-errchid
3022. ‘Abd-errchide
3023. ‘Abd-errcheed
3024. ‘abd-errchiyd
Trying to generate every possible name variation has a couple of obvious drawbacks. Name variations which are not in the list will not be found as matches, and perhaps an even greater issue is that of speed and size. Since multi-part names, particularly non-English names, generate an exponentially growing list of variations, searching through these lists takes time. Given a name with just three components and 20 possible variations per name, the number of possibilities is 203 (=8,000), a very large search space for just one name. Now multiply it by the number of names on a watch list! There are further challenges with the list method – how do you score matches when one of your 8,000 query variants matches more than one name in the database? It is also difficult to handle other types of variation, like nicknames, initials, and titles, without expanding the search space even more.
A benefit of the list method is that it is simple to maintain. When a user complains about a missed match, it’s easily added to the name database. However, easy maintenance may not be enough to offset the decreased speed. For applications with that require high-throughput over millions of names, such as watchlist screening, anti-money laundering (AML), and know your customer (KYC), this approach is likely to be too slow or require a lot of expensive hardware.
Edit distance method
Pros: Easy to implement
Cons: Limited to Latin-based languages; all swaps are weighted evenly, missing linguistic nuances
This approach looks at how many character changes it takes to get from one name to another. “Cindy” and “Cyndi” have an edit distance of 1 since the “i” and “y” are merely transposed, whereas “Catherine” and “Katharine” have an edit distance of 2 as the “C” turns into a “K” and the first “e” becomes an “a.”
Methods which look at the character-by-character distance between two names include Levenshtein distance, the Jaro–Winkler distance, and the Jaccard similarity coefficient. These approaches look at some combination of two factors (1) the number of similar characters and (2) the number of edit operations it takes to turn one name into the other — the operations being, insert, delete, and transpose.
Although these comparisons are quick, they do not capture linguistic nuance. All edits are given the same weight. Thus changing “c” to “p” is weighted equally as “c” to “k” although in English the latter substitution might more clearly indicate a similar name, as in “Catherine” vs. “Katherine.” Further, a one-to-many character mapping is not possible, as in the case of the Arabic character “sheen” ش which is frequently mapped to “sh” in English.
And, just as with the common key method, a non-Latin script name must first be transliterated to Latin script before the comparison can be executed.
Statistical similarity method
Pros: Matches across languages and scripts; offers greater precision
Cons: Slower performance; high barrier to entry as it requires training data and adjusting features etc.
A statistical approach takes hundreds, if not thousands, of matching name pairs and trains a model to recognize what two “similar names” look like so that the model can take two names and assign a similarity score.
A statistical model that has been trained on thousands of pairs of matching names offers high accuracy and the ability to directly match names written in different languages without first transliterating names to Latin script. This method has a higher barrier to entry, as collecting the matching names requires significant resources, but the accuracy may be well worth the effort. A downside is the slowness of execution. A system only using the statistical method to sift through millions of names to look for matches may be too slow to be feasible in high-transaction environments.
Word embedding method for organization names
Pros: Makes semantic matches that a spelling-centric method would miss
Cons: Only relevant to organization name matching
Organization names differ from human names in that variations may include synonyms that look and sound entirely different than the target name. In these cases, two names referring to one company are semantically similar but phonetically different. For example, a human can quickly infer that corporation, company, and group are all similar words often found in an organization’s name, but standard name matching techniques like the edit distance method would be unlikely to make the connection. In these cases, word embeddings can make the match.
Word embeddings are numerical vector representations of a word’s semantic meaning. If two words or documents have a similar embedding, they are semantically similar. For example, the embeddings of “woman” and “girl” are close to one another in the vector space, meaning they are semantically similar. Contrastingly, the embeddings of “whale” and “philosophy” are far from one another because they are not semantically related. Applied to organizations, the word embedding method recognizes that PennyLuck Pharmaceuticals and PennyLuck Drugs are most likely the same company.
Semantic similarity also works for matching organizational names in different languages. “United Nations” in Japanese is represented as 国際連合, however the characters 国際 actually translate to “international,” which isn’t the same as “nations.” Because both “nations” and “international” are in a similar vector space, text embeddings ensure that 国際 correctly matches with “nations.”

A two-pass, hybrid method: The best of breed
Hybrid approaches backfill weakness in one approach with the strength of a different approach. For example, a hybrid approach may first use the common key method for high recall, and then put its results through the statistical method for greater precision.
In the first pass, the faster common key method and high recall winnow the candidate pool to a smaller set of likely matches. This step is particularly vital when a list has names in different languages, first transliterating them — typically to English — before assigning metaphones. The second pass over the culled down list then uses a high-precision statistical method to filter the highest scoring matches to the top, making fine-grained distinctions between different matches.
Compared to the common key method alone, accuracy is greatly improved by this hybrid method. Instead of being locked into a coarse comparison of derived keys (for better or worse), the second pass of the hybrid approach takes a fresh look at the original names in their original scripts before scoring their similarity.
This hybrid method also avoids the weaknesses of the list approach by not relying on mass generation of name variations, but instead, uses (via the statistical model) the linguistic variations of names in each language. This linguistic knowledge of name variations also gives the hybrid approach an edge over the edit distance method, which cannot directly compare names in different scripts.
The result is a fast, accurate, name matching algorithm.




Frequently asked questions
What is fuzzy logic name matching?
Fuzzy logic name matching is a method that identifies whether two names are similar — even when spellings, formatting, or characters don’t match exactly. Instead of looking for perfect matches, it assigns similarity scores based on patterns and likelihood. This makes it far more effective for messy or inconsistent data. It’s widely used in identity verification, compliance, and data quality workflows.
Why does exact name matching fail in real-world data?
Exact name matching fails because real-world data is full of typos, formatting differences, missing accents, and cultural name variations. Even small changes like a swapped letter or shortened nickname break strict matching rules. Cross-language transliteration also introduces differences that exact matching can’t reconcile. As a result, organizations miss true matches and generate unnecessary false positives.
How does fuzzy matching work in AI systems?
AI-powered fuzzy matching analyzes names using similarity metrics, linguistic rules, and machine-learned patterns. It compares multiple features — not just letters — to determine how closely two names align. Advanced systems evaluate phonetics, common variations, and contextual clues like additional identifiers. This allows them to handle complex, multilingual, or imperfect data with much higher accuracy.
What are common use cases for fuzzy logic name matching?
Fuzzy logic name matching is used in KYC and AML screening, customer onboarding, fraud detection, and identity resolution. Investigators rely on it to link individuals across inconsistent or multilingual datasets. It also supports healthcare, government, and financial services by improving record matching. Anywhere names need to be compared reliably, fuzzy logic offers a more accurate alternative.
How does fuzzy matching reduce identity errors?
Fuzzy matching reduces identity errors by catching spelling mistakes, alternate versions of names, and cross-language inconsistencies that exact matching overlooks. It dramatically lowers false negatives — missed true matches — which improves security and compliance. At the same time, it reduces false positives by distinguishing between legitimately different individuals with similar names. This creates cleaner data and more confident decision-making across identity workflows.
What algorithms are used in fuzzy logic name matching?
Fuzzy logic name matching commonly uses algorithms like Levenshtein distance, Jaro-Winkler, Soundex, and other phonetic or similarity-based models. These algorithms score how similar two names are instead of requiring an exact match. Modern AI systems often blend multiple methods to improve accuracy. This hybrid approach works well in diverse, noisy, or multilingual datasets.
How does fuzzy matching handle spelling variations?
Fuzzy matching compares names character-by-character and sound-by-sound to understand how closely they align. It tolerates extra letters, swapped characters, missing accents, or minor typos without rejecting a match outright. By assigning similarity scores, it identifies likely matches even when data is imperfect. This makes it ideal for real-world data where inconsistencies are common.
How is fuzzy logic name matching used in watchlist screening?
In watchlist screening, fuzzy matching helps detect risky individuals even when their names appear with typos, aliases, or transliteration differences. It ensures that a slight spelling variation doesn’t allow someone to evade detection. By ranking potential matches, it helps analysts focus on the most relevant alerts. This reduces both false negatives and unnecessary investigations.
What accuracy benchmarks should fuzzy matching meet?
Fuzzy matching should deliver high precision and recall, ensuring it catches true matches while minimizing false positives. Benchmarks often aim for accuracy rates above traditional exact match systems, particularly in multilingual environments. Strong solutions allow tuning to meet industry-specific compliance requirements. Ultimately, accuracy should support confident, audit-ready decision-making.
How does fuzzy matching perform across languages?
Fuzzy matching performs well across languages when supported by multilingual rules, phonetic models, and transliteration handling. AI-based systems can learn cultural naming patterns and adapt to different scripts. This enables accurate comparisons between names written in Latin and non-Latin alphabets. High quality fuzzy matching maintains strong performance even in complex global datasets.
What fuzzy name matching solutions are best for compliance teams?
The best solutions for compliance teams combine multilingual fuzzy logic, high accuracy, explainable scoring, and the ability to scale across millions of records. Babel Street meets these needs with a patented two-pass name matching system that reduces false positives by up to 90% and supports 20+ languages and scripts.
How does Babel Street minimize false positives?
Babel Street minimizes false positives through a hybrid fuzzy-matching engine that blends phonetic, linguistic, and statistical models to evaluate 15+ types of name variations. Its two-pass matching approach ensures both high recall and high precision, eliminating unnecessary alerts while still catching difficult matches. Match scores give compliance teams full transparency into why two names were — or weren’t — considered a match.
Can fuzzy matching be tuned to risk tolerance levels?
Yes, Babel Street offers extensive configuration options so teams can adjust match thresholds, penalties, weighting, and precision/recall balance to match their risk profile. Its interface shows how parameter changes affect results in real time, allowing different settings for different workflows or user groups.
How does Babel Street support large scale name screening?
Babel Street is designed for high-volume environments, delivering realtime performance even when processing hundreds of millions of names. Its lightweight footprint enables deployment across cloud, on-premises, or distributed systems, including edge or portable devices for field operations. This scalability makes it suitable for national-level screening programs, border agencies, and global compliance teams.
How does fuzzy matching integrate with entity resolution?
Babel Street integrates fuzzy name matching with entity resolution by combining similarity scoring with contextual identifiers like addresses, dates, and aliases. Match results feed directly into broader analytics pipelines, helping teams link identities across datasets and languages with higher confidence. This unified approach allows organizations to move from simple name similarity to full-spectrum identity intelligence.