Writing annotation guidelines for entity extraction for adverse media screening in financial compliance
As much as we love to think our machine learning algorithms are the most important part of training up a model, they need human-annotated data to get started, which also — very importantly — are the benchmark for evaluating a model’s accuracy.
An inescapable, essential requirement to producing good training data is solid annotation guidelines. These guidelines distinguish correct from incorrect results. They also define the task and ensure that the annotation process is reliable and repeatable for independent human annotators. If the manual annotation process is not reliable, the supervised machine learning models may be confused by inconsistencies in the training data.
Getting started
Before starting, make sure your use case is clear and thoroughly understood. For what task and goal are you extracting entities? Without careful consideration, you may end up training a model that doesn’t provide useful results for your downstream processes.
Here are the steps that will take you through the process of writing annotation guidelines using the example of entity extraction:
- Decide what purpose or use case the NLP results will serve
- Decide what entities you need, and which ones are suited to machine learning
- Write a first draft of the guidelines
- Run a pilot annotation project with a quantity of data* (minimum of three annotators)Check for inter-annotator agreement to see where the annotators tagged text differentlyHave a meeting with the annotators to figure out what was unclear or erroneousUpdate the guidelines to address points of confusion
- Check for inter-annotator agreement to see where the annotators tagged text differently
- Have a meeting with the annotators to figure out what was unclear or erroneous
- Update the guidelines to address points of confusion
- Try the “results” (human-tagged entities) in your downstream process, and ask, am I getting the results I expect?
- Edit the guidelines.
*The quantity of data varies, but a rule of thumb is to do a pilot annotation project that both tries out the guidelines and trains the annotators before launching into the bulk of the work. Aim for annotators to independently tag for two days and produce just enough data so that you and they can review their disagreements together in a 30-minute meeting. At the beginning of an annotation project, you will need to meet with annotators frequently to review annotation disagreements and edit the guidelines. For more details on the annotation process, see our blog post A Day in the Life of… Building a New Entity Extraction Model.
Revise, revise, revise
It’s important to remember that writing guidelines is an iterative process. The pilot annotation project is as much a training session for the annotators as it is a proof-of-concept to confirm which entities you should be annotating. You may find yourself asking whether a different extraction method is better suited to a particular entity type. When you work through the inter-annotator agreement with your annotators, the question of which tagging was correct might require you to refer back to your use case, and refine the purpose your NLP will be serving. You will definitely have to update your guidelines to address ambiguous and borderline cases that come up during discussions with annotators.
What will you do with the NLP results?
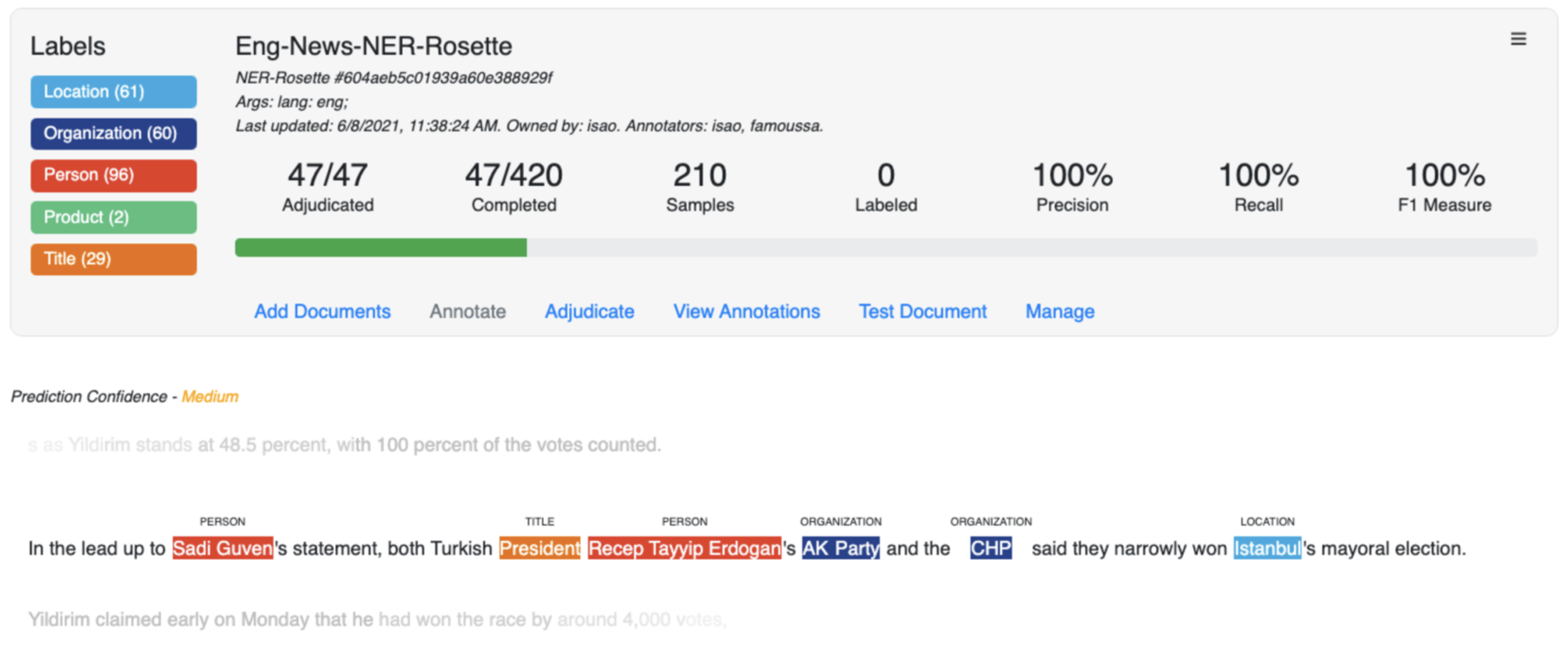
For the purpose of illustration, let’s suppose we are writing annotation guidelines for entity extraction, and that these entities will feed into a system that is detecting negative news about certain individuals or organizations — aka, adverse media screening for financial compliance. (Banks are heavily penalized by regulators if they transact business with people and organizations who are involved in crime and misconduct.)
Financial regulations require enhanced screening of politically exposed persons (PEPs) who tend to be well-known and well-connected. The financial compliance system needs to pull up enough information to know that:
- It found the right person to screen — and not someone else with the same name
- It is negative news about the person — and not just generic news, as well-known people frequently appear in stories.
The corpus will consist of news and financial news articles.
Based on this task, we want to extract people, locations, organizations, titles of people, dates, currency, and types of crime and misconduct. For example, entities like locations, organizations, dates, and titles can help determine which “Brandon Smith” you have found (the basketball player). Suppose that in our corpus, dates, currency, and types of crime are too sparse (don’t appear often enough) for machine learning. Follow this rule of thumb: You need a minimum of 1,000 instances of each entity type, but the more the better.
For sparse entities, use a method other than machine learning. Dates are suited to pattern matching, as they are written in set formats. Types of crime are possibly suited to entity lists, but we might also consider leveraging the entity extraction to build an event extraction model around specific types of criminal activity.
What to include in your annotation guidelines
Now let’s go through the steps for writing guidelines in greater detail. Suppose after evaluating your downstream needs, you decide to tag names of people, locations, organizations, nationalities, and titles of people.
Define these entity types and give examples of entities and non-entities. The essential components to named entity recognition (NER) guidelines are:
- Motivation and description of the entity types of interest
- Several positive examples of each type (“Do annotate X in the following context: ____”)
- Several negative examples of each type (“Do NOT annotate X in the following context:____”), including non-entities and instances of ambiguity between different types.
- Instructing annotators to tag obvious misspellings of entities, as the misspelled words are still a true signal of where a real entity would appear
- Instances where annotators had significant disagreements during the iterative development process usually are good examples.
Define how will you handle:
- Punctuation — Do you tag embedded punctuation?
- Fictional entities — Do you tag fictional entities?
- Metonyms — Do you tag a nominal expression that represents an entity associated with a different entity? Example: “The White House condemned the attacks on the refugees.” Sometimes White House is a location, but here it is used to reference the executive branch of the U.S. government.
- Proper nouns as verbs or compound nouns — The answer depends on your downstream needs. For financial compliance, this is likely unnecessary.
- Titles — What titles do you tag? There is an enormous range of titles from Mr. and Ms. to simple occupations like “dancer” or “lawyer” to long descriptive titles like “VP, Big Data Lab, and Senior Fellow, Information Research and Development.” You also need to decide if it is useful to tag a title that doesn’t appear with a person’s name. Example: “The HR manager sent out a memo.”
More questions for you to answer:
- When is a location a nationality? Is a location used as an adjective always a nationality? Does it depend on context?
- How do you annotate adjacent locations? When do you tag adjacent locations such as “We visited Boston, New York, and Philadelphia”?
- Do you tag location qualifiers? It’s clear one should tag “New York” as a location, but what about “the region of Upper State New York…” We might say to only tag “Upper State New York” in English, but what about in Japanese, where the whole phrase looks like one word?
- Do you annotate generic and specific instances of an entity? It’s easy to say “annotate March 13, 2020,” but what about “mid-June” or “from dawn to dusk”?
- How do you handle embedded entities? Titles of people often include an organization name. Do you tag the longest entity or does your task require tagging the location and the organization within the title?
Last words
The above is just a starting point for writing annotation guidelines. Ultimately, seeing what is confusing for annotators will shape what your guidelines cover. Always keep in mind the purpose of the entities being extracted. If your downstream analysis is going to be doing event extraction where time is really important, maybe you should extract more than dates. You may want to include time phrases, such as “from 6 p.m. to 9 a.m.” or “two nights ago.”
Ultimately, an easy-to-understand annotation guide with plentiful examples of each rule (with examples of what to tag and what not to tag) will help your human annotators produce consistently tagged data that will enable your model to become accurate and yield useful results.