Understanding the Difference Between Open and Targeted Relationship Extraction
Who’s in your data, and how are they connected?
You may have heard about relationship extraction and wondered what this natural language processing (NLP) innovation is. Relationship extraction is the automated detection and classification of semantic relationships between entities in text. It goes beyond automatically adding metadata to articles, to “writing” profiles and reports about a person, place, or organization.
For example, this technology can automatically compile the “info boxes” that are ubiquitous in Wikipedia articles.
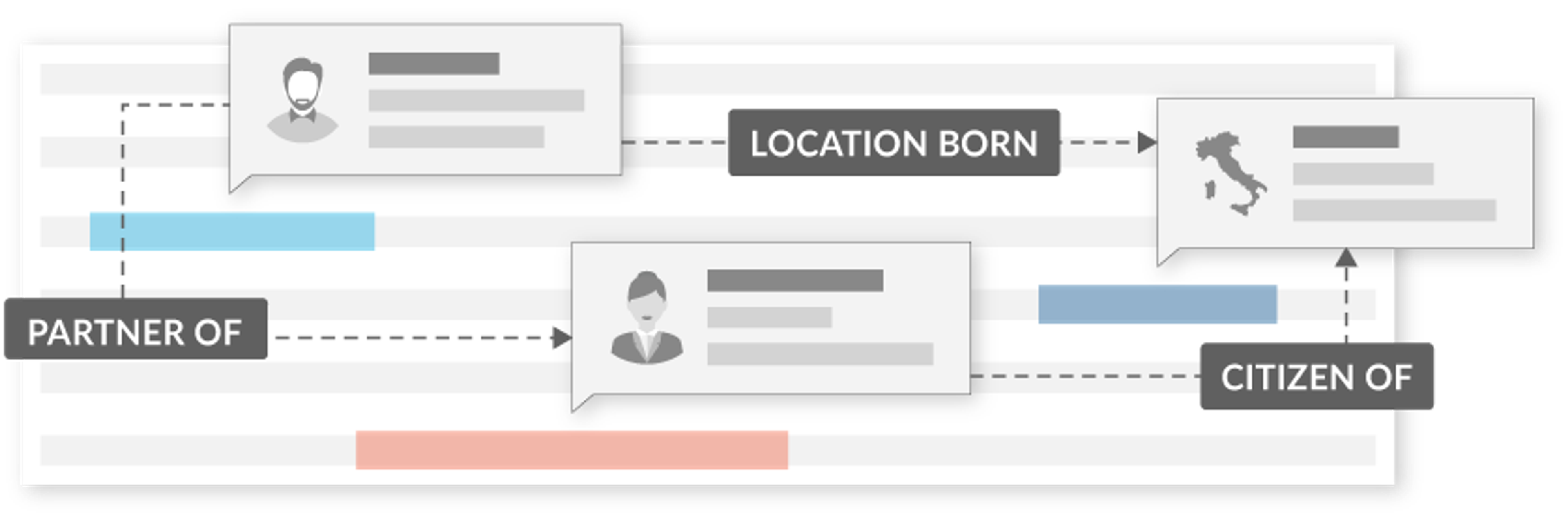
Think of relationships as “properties” of an entity. Martin Luther King Jr. is related to “born in Atlanta, GA” and “graduated from Morehead College.” Or about a company, the relationships might be how many employees it has, who is the president, and who are the competitors. These relationship data points are the raw materials for building a knowledge graph.
Relationship extraction comes in two modes – open and targeted – which we’ll discuss in this blog.
What is relationship extraction?
Relationship extraction begins with automatically finding the people, places, organizations and entities in unstructured text. Named entity recognition (NER) or entity extraction is accomplished through a combination of rules expressed as regular expressions, entity lists, and statistical modeling.
Understanding how entities connect and interact with one another brings entity extraction to the next level, powering knowledge graph generation for more comprehensive data understanding. From these entities, relationship extraction automatically detects and classifies the types of relationships between entities.
Open relationship extraction
Relationship extraction algorithms can be either open or targeted. Open relationship extraction returns text snippets of a relationship and its arguments. Consider the following sentence:
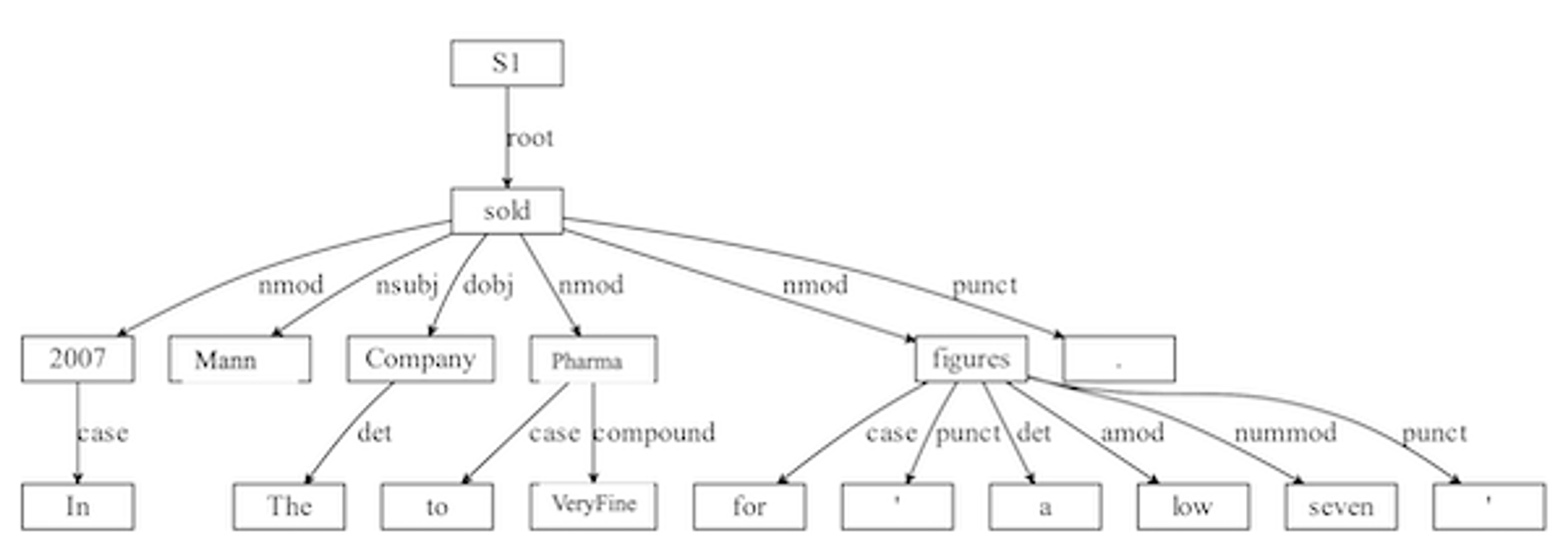
“Pennyluck Drugs was founded by investor and entrepreneur Guy Mann in 2005. In 2007 Mann sold the company to VeryFine Pharma for “a low seven figures.”
An open relationship extractor returns the following:
- Pennyluck Drugs; was founded; by investor and entrepreneur Guy Mann; T:in 2005
- Mann; sold; the company; to VeryFine Pharma; for “a low seven figures; T:In 2007
Aligning open extractions like these to a knowledge base is difficult. It is not clear that “investor and entrepreneur Guy Mann” is the same entity as “Mann,” and the second string does not make the connection that “the company” is referring to “VeryFine Pharma.”
Most relationship extraction tools on the market today are open extractors.
Targeted relationship extraction
Building upon the process above, when relationship extraction algorithms are pre-trained to identify specific relationship types, they produce targeted relationship extraction. While open relationship extraction benefits from the fact that it is not constrained by a limited set of relationship types, the results are still only semi-structured, meaning they still require some human interpretation to parse. Targeted relationship extraction produces structured results that are more readily digestible by downstream applications such as knowledge graphs.
Targeted relationship extraction uses a deep convolutional neural network to identify the exact actions connecting the entities and other related information within a sentence. Machine learning methods applied over parse trees and entity mentions analyze the connection, and then return the components of the relationships.
For example, a targeted relationship extractor returns the following relationships from the same text as above:
- Pennyluck Drugs (Q123); FOUNDER (R1); GuyMann (Q456);
- Pennyluck Drugs (Q123); ACQUIRED-BY (R2); VeryFine Pharma (Q789);
Targeted relationship extractors use entity linking to connect each entity mention back to a knowledge base such as Wikipedia or an internal database of known entities. Entities that link back to the same knowledge base ID are resolved into one cohesive entity. In this case, “investor and entrepreneur Guy Mann” and “Mann” are resolved back to Guy Mann (Q456). Similarly, the extractor recognizes that the “company” referred to in the second sentence is the same as in the previous sentence.
Lastly, the text snippets indicating relationships and their arguments are classified using patterns that were induced from external sources, such as Wikidata. That means that phrases like “he founded,” “they co-founded,” and “she started” can all be resolved to the same relationship type: “FOUNDER.”
Resolving these relationships means that the arguments (predicates, temporals, etc.) are not just strings, but identifiers in a database that can be utilized to construct knowledge graphs, make faceted search queries, enable link analysis between entities, and supply answers in automated Q&A systems.
Learn more
Interested in diving even deeper into the technology behind relationship extraction? Check out some additional reading:
- “Review of Relation Extraction Methods: What Is New Out There?” Natalia Konstantinova; University of Wolverhampton
- “A Review of Relation Extraction” Nguyen Bach, Sameer Badaskar; Carnegie Mellon University